C++STL泛型进阶
本文最后更新于:2023年4月5日 晚上
在STL中常见对象函数,可变参数模板等语法,在GNU4.9中使用大量typedef,但目前using使用的更多。
本文是侯捷STL源码剖析的笔记,源码内容以GNU2.9和GNU4.9为主,有点过时,现在源码非常复杂,很难直接入手,但STL使用的思想基本没有变化,因此即使侯捷STL过时,但也能收获颇多,总体来说其中的模板递归,函数对象,traits等内容留下的影响最深,STL实现非常奇妙
C++STL六大部件概览
- 容器Containers
- 分配器Allocators
- 算法Algorithms,函数模板
- 迭代器Iterators
- 适配器Adapters
- 仿函数Functors
迭代器可以看做是一种泛化的指针,vector<int,allocator<int>>分配器有缺省值,一般可以省略,以下是一段使用示例
1 | |
begin()指向第一个元素,end()指向最后一个元素的下一个位置
C++11后有range-based for statement简化遍历,以及智能指针auto
1 | |
结构分类:序列容器,关联容器,无序容器(Unordered Containers,顺序不确定,由hashtable实现)
C++11新增array,forward-list,unordered containers,
array一段固定的空间,无法扩充,vector一端可扩充,均为连续空间,deque两端可扩充,分段连续list双向链表,forward-list单向链表,均为非连续空间set,map,multimap,multiset使用红黑树实现unordered map,unordered map实际是hash table中的separate chainsequence containers
vector当空间不够,扩容为原来的2倍,将原来的元素搬到新的vector中,可以通过capacity()查看分配的空间list有自己的排序函数,每次扩充一个节点forward_list没有back(),size()方法,有自己的排序函数sort()deque分段连续,一段称为bufferstack与queue内部使用deque实现,有的地方认为stack与queue是Adapter,分别具有先进后出,先进先出的特点slist也是单向列表,但不是STL内容,在ext/slist头文件中
Associative Containers
multiset自己有find函数,查找较快,红黑树结构multimap插入不能使用[],只能通过insert()插入,红黑树结构
unordered containers
unordered_multiset通过hash分配给各个bucket,每个bucket有一个链表放元素,可通过bucket_count查询bucket个数,bucket数量多于元素数量,自己又查找方法unordered_multimap与unordered_multiset类似,使用hash table做底层
基础知识
- Dev-C++的STL源码路径
...\Dev-Cpp\MinGW64\lib\gcc\x86_64-w64-mingw32\4.9.2\include\c++\bits - C++标准库>C++标准模板库
- 标准库以head files形式存在
- C++标准库的header files不带后缀,如
#include<vector> - 新式C
header files不带.h后缀,如#include<cstdio> - 旧式的
header files带.h后缀,仍可用,#include<stdio.h> - 新式
headers的所有组件封装在namespace std中;旧式headers内组件不会封装在namespace std中
OOP与GP
OOP(object-oriented programming)面向对象,数据与方法放在一起,如list中的sort()方法
GP(generic programming)泛型,数据与方法分离,将容器与算法(对应数据与方法)分开,两者通过iterator沟通
运算符重载
参考资料
包含哪些操作符不能重载,能重载的操作符如何重载
模板
类和函数都有模板,在声明时,类需要<>指明数据类型,但函数不用<>指明数据类型
1 | |
泛化与特化
泛化,特化,偏特化,例子如下,优先匹配特化类型,没有则采用泛化类型
1 | |
分配器
GNU4.9中,在__gnu_cxx命名空间,需要#include<ext\array_allocator>,有以下分配器
- array_allocator
- mt_allocator
- debug_allocator
- pool_allocator
- bitmap_allocator
- malloc_allocator
- new_allocator
1 | |
各个版本中的分配器
- VC6 STL对allocator的使用,没有特殊设计
- allocate时,调用operator new,最底层是使用malloc(在使用malloc申请空间时,多个小字节元素申请的空间overhead会很大,每一块空间需要记录空间大小,因此有较多额外开销)
- deallocate,调用operator delete,最底层调用free
1
2
3
4// ()临时对象
int* p = allocator<int>().allocate(512, (int*)0);//给出0或1等都无所谓
// 在归还内存时还需要告知申请时的空间
allocator<int>().deallocate(p, 512);
- BC5中的allocate和deallocate与VC相同,无特殊设计
- GNU2.9中allocator的allocate与deallocate与VC相同,无特殊设计,默认使用alloc分配器。GNU2.9中alloc有独特的设计,在
<stl_alloc.h>中alloc通过16个类似链表的东西实现内存分配,每一块增加8,能够申请一大块空间,避免额外开销来记录每一个空间的大小 - G4.9,默认使用allocator,
<bits/allocator.h>中的allocator类继承new_allocator类(在<bits/new_allocator.h>中),但new_allocator中的allocate和deallocate方法与VC一致,在G4.9中有很多扩展allocator,其中的pool_alloc就是G2.9的alloc
迭代器与iterator traits
- 迭代器需要有5种
associated types(迭代器作为算法和容器的桥梁,在使用算法时,迭代器需要给算法提供这5个东西),能够得出迭代器category(种类),difference(迭代器距离),value(被指元素数据类型),reference和pointer(后两种在标准库中未被采用) - 注意:
difference_type大小超过其数据类型(定义中的数据类型是ptrdiff_t,实际是unsigned int)所允许的大小时可能会失效 - 有两种迭代器
class iterators和non-class iterators(即pointer,退化的迭代器),前者可以方便的获取5种associated types,后者则不行,因此需要iterator traits萃取机,分离两种迭代器,traits如果接收pointer将使用偏特化1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19template<class T>
struct iterator_traits<T*>
{
typedef random_access_iterator_tag iterator_category;
typedef T value_type;
typedef ptrdiff_t difference_type;
typedef T* pointer;
typedef T& reference;
};
template<class T>
struct iterator_traits<const T*>
{
typedef random_access_iterator_tag iterator_category;
typedef T value_type;
typedef ptrdiff_t difference_type;
typedef const T* pointer;
typedef const T& reference;
};
迭代器种类
五种迭代器category,下一行继承上一行的迭代器(通过类提高算法复用,如实现input_iterator对应的算法,其子类若无特殊性质也可以使用该算法)
- input_iterator_tag/ouput_iterator_tag
- forward_iterator_tag
- bidirectional_iterator_tag
- random_access_iterator_tag
1 | |
容器
下面示例中缩进表示后者由前者衍生,复合关系,即后者中有一个前者,通过sizeof()函数可以查看容器的大小(与容器的size()方法不同,是查看容器中的指针等结构所占大小),如cout << sizeof(vector<int>) << endl;
1 | |
C++11中slist改名为forward_list,hash_set,hash_map改名为unordered_set等,并新加array
list
list实际是一个双向循环链表,并且具有额外的一个元素,即最后一个元素的下一个元素。iterator是list中的一个类,这个类对指针常用的操作符有重载- 版本区别:
- 在GNU2.9中列表的指针使用
void*类型,迭代器需要三个参数<T,T&,T*>,链表类与相关的类关系不复杂,迭代器定义中含有5种associated types; - 在GNU4.9版本中迭代器只有一个参数
<T>在迭代器内实现T*和T&,并且链表指针成为指向自己的类型,即_list_node_base,链表类的相关类增加出现继承,组合等多种关系,迭代器定义中含有5中associated types。
- 在GNU2.9中列表的指针使用
iterator++返回不带reference所以不能++两次,与int i=0;i++;同理,但++iterator返回reference,可以前++两次
vector
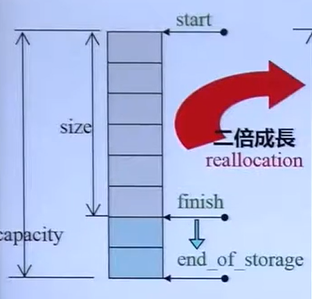
- vector扩充。当vector空间不够时会在内存中找到另一块2倍大的空间(如果找不到则生命结束),然后将原来的元素拷贝过来,并将原来的元素删除,因此在使用时需要注意扩容问题,vector中的各个指针如下图所示
- 对于空间是连续的容器往往会提供
[]操作符 - 版本差别:
- G2.9中使用一个指针做迭代器(退化的迭代器),因此在使用迭代器时先输入萃取机
traits再获取5个associated type - G4.9增加了继承关系
- G2.9中使用一个指针做迭代器(退化的迭代器),因此在使用迭代器时先输入萃取机
vector在扩容中的优化:
- 使用
emplace_back()代替push_back(),尽量避免不必要的对象拷贝操作。emplace_back()在容器末尾直接构造元素,而push_back()需要先构造一个对象,再将对象拷贝到容器中。 - 避免频繁插入或删除元素,这会导致
vector容器的动态扩容和缩容,影响性能。 - 可以先将元素保存到一个临时
vector中,再使用swap()函数一次性将所有元素插入到目标vector中,使用浅拷贝。
array
array是不能扩充的,一经创建大小就不能改变,没有构造函数和析构函数,只有pointer(退化的迭代器),4.9版本也多了很多继承关系
deque
- 分段串联起来,使用一个类似
vector的结构,每个位置存储指向对应buffer的指针,表现上看是(分段)连续的,可以使用[]访问元素 deque的迭代器是一个类,迭代器含有first(buffer开始位置),cur(当前位置),last(buffer结束位置,与first共同确定buffer的边界),node(在控制中心vector的位置,在一个buffer走到尾时会使用),deque含有三个迭代器,start,finish和iteratordeque的插入函数insert()会根据被插入元素位置前后的元素个数决定,把其余数据向头端推动或者向后端推动- 为了模拟连续空间。对大部分操作符进行了重载。
- 版本区别。G2.9版本
deque是单一的一个类,可以指派buffer_size,G4.9变为多个,且不能指定buffer_size,512/元素大小作为buffer大小 - 扩容。
deque的控制中心使用与vector类似的结构,因此当控制中心满后也需要扩容,与vector扩容类似,但deque在将原来元素复制到新空间时,会复制到新空间的中间(给前方留出空间)
stack,queue
- 底层默认使用
deque实现,只需要调用deque的一些操作即可 - 不提供迭代器,不可遍历
- 模板类的第二个参数是
class Sequence=deque<T>即默认底层使用deque,也可使用list做底层实现,但deque效率更高;都不可选择map或set作为底层 - 区别:
queue不可使用vector做底层,但stack可以使用vector做底层
rb-tree(非公开)
- 红黑树采用中序遍历,有两种
insertion操作,insert_unique()插入唯一值和insert_equal()插入值可以重复 - 红黑树的
header节点是一个空的仅有辅助功能的节点 - 迭代器可以修改元素值
- 红黑树模板有5个参数,
key,value(key+data),keyOfValue(如何取到key),compare(比较规则),Alloc(分配器)
set/multiset
- 以红黑树为底层,
value与key一致,value就是key,不能使用迭代器修改元素值(因为key就是value),通过const_iterator实现禁用迭代器修改 set的insert使用红黑树的insert_unique();multiset的insert使用insert_equal()set所有操作依靠红黑树的方法实现,因此也可以将set看做一个container Adapter
map/multimap
- 以红黑树为底层,要求放入四个模板参数(
class Key,class T,class Compare=less<Key>,class Alloc=alloc)后两个参数有默认值,因此一般只需要给出两个参数即可,调用的底层的红黑树参数Key, pair<const Key,T>, select1st<pair<const Key,T>>, Compare, Alloc,在VC6中没有select1st() - 禁止修改
key而可以修改data,通过设置key为const类型实现 - map可以通过
[]修改或插入值,但multimap不能。[]返回key所对应的data,如果key不存在则新建一个以key,data=默认值的节点并被返回,[]内部先lower_bound()再调用insert(),因此insert()效率更高
hashtable(非公开)
- 同一位置出现多个元素使用单向链表(VC使用双向链表),即
separate chaining hashtable(实际使用vector+list)中的每一个位置称为一个bucket,一般bucket数量会选择素数,当一个bucket所挂的链表过长时(长度超过总bucket数量),将hashtable进行扩充(扩充为原来2倍附近的素数)以便将元素打散重排,没扩充一次都会将所有元素重新排列hashtable要求给出六个模板参数<class Value,class Key,class HashFcn, class ExtractKey, class EqualKey, class Alloc=alloc>,HashFcn仿函数,用于计算编号放入对应的bucket;ExtractKey如何取出key;EqualKey指定什么叫key相等。hash<>具有多个特化版本,用于产生编号以便排序- 迭代器根据链表是否为单向或双向,使用
bidirectional和forward
unordered_set,unordered_multiset,unordered_map,unordered_multimap
bucket_size(i)查询第i个bucket含有的元素个数bucket数量一定大于元素个数
算法
算法首先要根据迭代器获取必需的信息(5种associated type),iterator traits与type traits对算法效率有较大影响,算法需要根据数据特性选择最高效的算法
部分算法举例
accumulate(InputIterator first,InputIterator last,T init,BinaryOperation binary_op)将first至last中的元素使用binary_op操作累计给init并返回for_each(InputIterator first,InputIterator last,Function f)对[first,last]的元素使用函数freplace(ForwardIterator first,ForwardIterator last,const T&old_value,const T&new_value)将[first,last]中所有等于old_value的元素更换为 new_valuereplace_if(ForwardIterator first,ForwardIterator last,Predicate pred,const T&old_value,const T&new_value)将[first,last]内满足pred条件(pred返回true or false)的取代replace_copy(InputIterator first,InputIterator last,OutputIterator result,const T&old_value,const T&new_value)将[first,last]中等于old_value的元素放入result区间中count(..)(循序计数),count_if(..),find(..)(循序查找),find_if(..),sort(..)(快排)五种函数使用方式类似(省略了参数),在部分容器中有自己的同名成员函数- 容器不带
count(),find(..)方法:array,vector,list,forward_list,deque - 容器带有
count(),find(..)方法:set/multiset,map/multimap,unordered_set/unordered_multiset,unordered_map/unordered_multimap - 除了
list和forward_list都没有成员函数sort(),且不能使用算法中的std::sort()(set等容器自带排序)
- 容器不带
binary_search()使用二分查找,必需是已排序的容器,底层调用lower_bound()lower_bound(ForwardIterator first,ForwardIterator last,const T&val)将val插入已排序容器所能存在的最低点,upper_bound(ForwardIterator first,ForwardIterator last,const T&val)将val插入已排序容器所能存在的最高点
Functors仿函数
把类当做函数用,只为算法服务,比如排序默认使用从小到大,通过仿函数实现从大到小排序,都是对操作符()进行重载,是个对象但像函数
三类仿函数:
- 算术类Arithmetic
- 逻辑运算类Logical
- 相对关系类(比大小)Relational
1 | |
STL中的仿函数都继承了binary_function<T,T,T>或者另一个类unary_function(),其类的实现示例如下,使仿函数可适配化,没有继承binary_function<T,T,T>在一些算法(比如sort())中可以使用,但当算法需要适配器时将无法使用
1 | |
适配器
在仿函数,迭代器,容器中都有适配器出现typename使用typename关键字修饰,编译器将这个名字当做是类型(避免在编译时才能确认是变量还是类型)
- 容器迭代器:
stack,queue - 函数迭代器:
binder2nd(const Operation&op,const T&x)(已被bind()取代),将op的第二个参数绑定为x,要求op必须继承binary_function;not1(const Predicate& pred)bind()绑定函数,使用_2(第二实参),_1(第一实参)等作为占位符,可以指定模板类型,表示返回类型,可以绑定四种类型functions,function objects,member functions,data members1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39// bind example
#include <iostream> // std::cout
#include <functional> // std::bind
// a function: (also works with function object: std::divides<double> my_divide;)
double my_divide (double x, double y) {return x/y;}
struct MyPair {
double a,b;
double multiply() {return a*b;}
};
int main () {
using namespace std::placeholders; // adds visibility of _1, _2, _3,...
// binding functions:
auto fn_five = std::bind (my_divide,10,2); // returns 10/2
std::cout << fn_five() << '\n'; // 5
auto fn_half = std::bind (my_divide,_1,2); // returns x/2
std::cout << fn_half(10) << '\n'; // 5
auto fn_invert = std::bind (my_divide,_2,_1); // returns y/x
std::cout << fn_invert(10,2) << '\n'; // 0.2
auto fn_rounding = std::bind<int> (my_divide,_1,_2); // returns int(x/y)
std::cout << fn_rounding(10,3) << '\n'; // 3
MyPair ten_two {10,2};
// binding members:
auto bound_member_fn = std::bind (&MyPair::multiply,_1); // returns x.multiply()
std::cout << bound_member_fn(ten_two) << '\n'; // 20
auto bound_member_data = std::bind (&MyPair::a,ten_two); // returns ten_two.a
std::cout << bound_member_data() << '\n'; // 10
return 0;
} - 迭代器适配器,
reverse_iterator,inserter,在copy()函数中,是直接将一段数据复制到(通过赋值实现)另一个容器中,如果另一个容器空间不够将出错,通过inserter可以将赋值操作改为insert(),从而不用担心空间问题。 istream_iterator,ostream_iterator1
2
3
4
5
6
7
8
9
10#include <iostream> // std::cout
#include <functional> // std::bind
#include<vector>
#include<iterator>
int main() {
std::vector<int> a = { 1,6,3,8,3,0,123 };
std::ostream_iterator<int> out_it(std::cout, ",");//内部对指针++,相当于再次执行对应操作
std::copy(a.begin(), a.end(), out_it);
return 0;
}1
2
3std::vector<int>c;
std::istream_iterator<int>iit(std::cin), eos;//在这一行就已经开始等待输入了
copy(iit, eos, std::inserter(c, c.begin()));
STL周边
hash_function通过调用对象函数实现递归处理tuple使用可变参数模板(将n个模板参数分解为1+(n-1)然后递归处理),能够使用任意数量任意种类的参数,通过继承实现递归处理,如声明tuple<int,int,double>将被递归为:tuple<int,int,double>继承自tuple<int,double>继承自tuple<double>继承自tuple<>1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37// tuple实现部分代码,与源码变量名称有差别
template <class Head, class... Tail>
class tuple<Head, Tail...> : private tuple<Tail...> { // recursive tuple definition
public:
};
// tuple使用示例
#include <iostream> // cout
#include<iterator>
#include<functional> //tuple
#include<vector>
#include<complex> //complex
using namespace std;
struct a{
string a1;
int a2;
int a3;
complex<double> a4;
};
int main() {
cout << sizeof(string) << endl; //28
cout << sizeof(complex<double>) << endl; //16
cout << sizeof(int) << endl; //4
cout << sizeof(tuple<string, int, int, complex<double>>) << endl;//64
cout << sizeof(a) << endl; //56
tuple<int, double, int>t1(31, 4.2, 123);
cout << sizeof(t1) << endl; //24
cout << get<0>(t1)<<" "<<get<1>(t1) << endl;
auto it = make_tuple(23, "2332", 2.3);
typedef tuple<int, int, string> t;
typedef tuple_element<1, t> tmp;
cout << typeid(tmp).name() << endl;
}type_traits。所有的type_traits可见cplus网站,用于获取对象的信息,对于自己写的类也可以使用,一个类带指针就需要析构函数,不带则不用析构1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17// is_void等即为type_traits,下面是部分type_traits展示,使用如下所示
template<typename T>
void type_test(const T& x) {
cout << "type traits for type: " << typeid(T).name() << endl;
cout << "is_void: " << is_void<T>::value << endl;
cout << "is_integral: " << is_integral<T>::value << endl;
cout << "is_floatinf_point: " << is_floating_point<T>::value << endl;
cout << "is_arithmetic: " << is_arithmetic<T>::value << endl;
cout << "is_signed: " << is_signed<T>::value << endl;
cout << "is_unsigned: " << is_unsigned<T>::value << endl;
cout << "is_const: " << is_const<T>::value << endl;
cout << "is_class: " << is_class<T>::value << endl;
cout << "is_function: " << is_function<T>::value << endl;
}
int main() {
type_test(string());//放入一个临时对象
}moveable对效率有较大影响,深拷贝和move construct(也称浅拷贝),深拷贝开辟一块空间将指针和数据都拷贝,浅拷贝只拷贝了指针,因此浅拷贝很快,使用浅拷贝需要确保原数据不再使用(临时对象拷贝可以用move),对于使用了move construct的类在析构时需要先判断指针是否为0,然后再delete指针。在vector中使用浅拷贝,相当于只把新容器的指针指向(新建三个指针)被copy容器的数据,即两个容器数据共享,两者指针指向相同。类中是否有浅拷贝可以通过type_traits获取